Corn futures are probably the most liquid agricultural commodity futures worldwide, and are used by producers, consumers and speculators alike. This blog post looks for the typical stylized facts that are often found in financial time-series.
Futures – Contract Details
Corn futures are traded on the Chicago Board of Trade CBOT (now part of the CME group). The CBOT lists various corn futures with different expiry months: CN (July), CU (September), CZ (December), CH(March), CK (May). Buying one future contract gives the buyer the right (and obligation!) to receive 5,000 bushels of corn at the expiry of the contract in one of the many designated elevators in the US midwest.
Usually the front month contract is the most liquidly traded, and often the December contract CZ serves as the main corn price index, being the first contract where the bulk of the new crop corn can be delivered. The full contract details of CBOT corn futures are available on the CME website.
Price Levels
Before diving into stylized facts of corn prices we’ll visualize the raw price series.

Each color represents one December futures contract. A few things directly jump out: Corn traded consistently between 200 cts/bu and 400 cts/bu from 1988 until 2006. From 2007 – 2014 the prices exploded and traded anywhere between 350 and 800 cts/bu. From 2015 onward prices settled lower again, but still higher than during the pre-2006 era. The large price increases and high volatility of the price between 2007 and 2014 is usually attributed to a combination of adverse weather conditions, ethanol fuel mandates, higher oil prices, the financial crisis, and a generally higher investor interest for commodities.
However there is a caveat: Comparing historical with current price levels can be misleading due to inflation over the same time-period. Below chart inflates historical prices to July 2020 equivalents using the US CPI (CPIAUCSL):

The price levels look quite different when using inflation-adjusted prices. While nominal prices were stable between 1988 and 2007, real corn prices continuously lost in value during the same period and reached their lows between 2003 and 2005. Current price levels are above pre-crisis levels.
Throughout the rest of the blog-post we’ll use the nearby December contract as a proxy for the corn price, and roll to the next year’s contract the day before the first notice day. All the analysis involving returns excludes data from the first notice days to avoid spurious roll returns.
Stylized Fact: Non-normality of Returns
It is well known that most financial returns are not normally distributed – does the same hold true for Corn?
Yes. Nominal (non-inflation adjusted) daily log-returns of the nearby December Corn future follow a heavy-tailed distribution. The fat tails are clearly identifiable by the positive kurtosis and the shape of the QQ-plot.

Stylized Fact: Volatility Clustering
Another often cited observance in financial time-series is volatility clustering. Volatility clustering of financial returns describes the fact that “large changes tend to be followed by large changes, of either sign, and small changes tend to be followed by small changes.” as stated by Mandelbrot [3]. Corn is no exception, and exhibits both the typical decaying auto-correlation structure of squared log-returns and the absence of auto-correlation between the (linear) log-returns.


Volatility clustering is also visually observable by looking at the time-series of the daily log-returns:

Stylized Fact: Seasonality of return distribution
Annual seasonality is not typically a feature of financial time series, but is often present in agricultural commodity prices. Corn is a crop with a yearly growing and harvesting cycle, which clearly impacts the return distribution. Below chart visualizes the variance of the daily log-returns and shows a yearly seasonality. This also partially explains the strong volatility clustering, even though seasonality is generally not required to explain this effect.

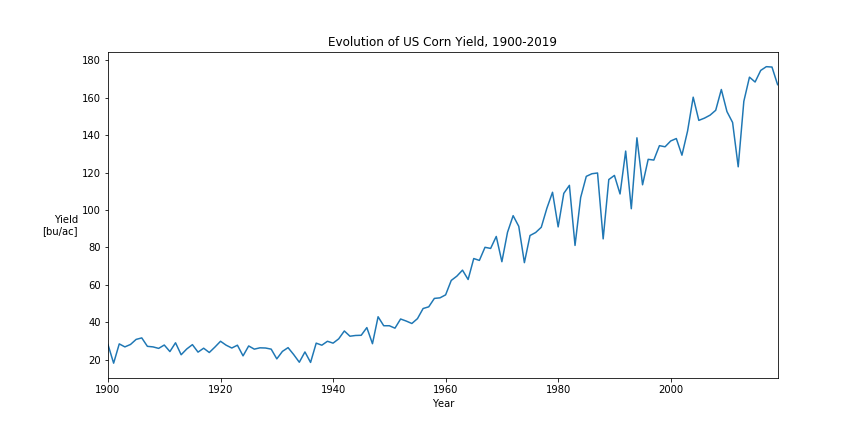
Checking the return distribution by calendar month further confirms the seasonal pattern: the return distribution during (US-) summer months is much wider than during (US-) winter months. The fundamental reason for this is the growing cycle for US corn. US corn is planted between April and June, and usually harvested from September to November. While the overall supply uncertainty is largest before any corn is planted, the daily volatility peaks during summer months when weather is critical for corn development and determining the final production size [2].


Summary
Corn futures exhibit the typical stylized facts of financial time-series such as volatility clustering and non-normal fat-tailed returns. Additionally to these traditional stylized facts, corn also exhibits a strong seasonality of return magnitudes (or volatility) due to the inherent annual growing cycle of the corn plant.












 , and all kind of interesting things are happening at that point:
, and all kind of interesting things are happening at that point: